Merge Job Task
This page contains these elements:
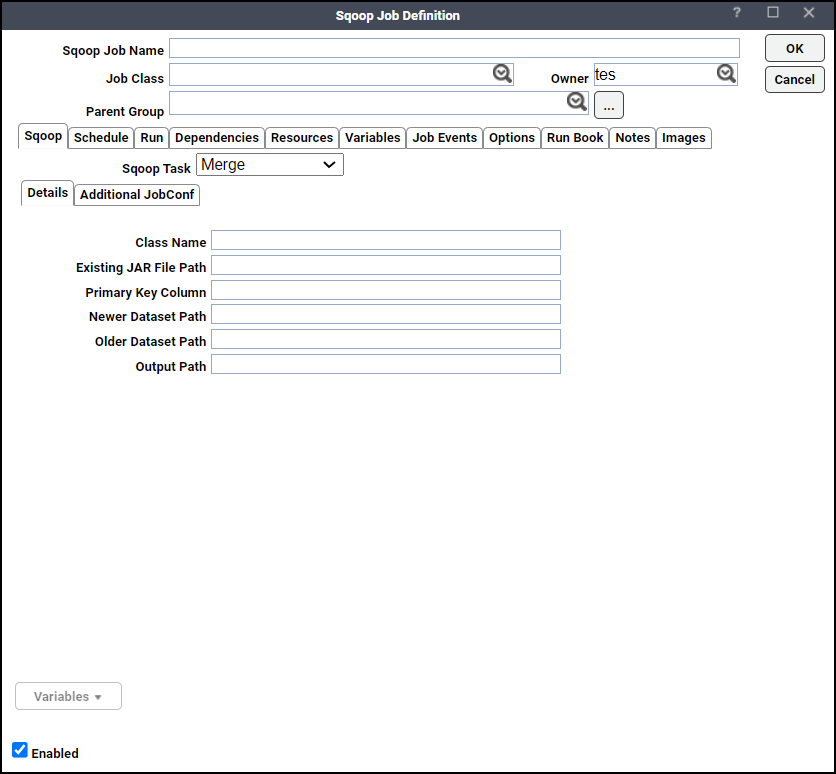
Details Tab
This tab contains these elements:
Note: You can click Variables to insert a predefined variable into a selected field on this tab.
-
Class Name – The name of the record-specific class to use during the merge job
-
Existing JAR File Path – The name of the jar to load the record class from.
-
Primary Key Column – The name of a column to use as the merge key. When merging the datasets, it is assumed that there is a unique primary key value in each record.
-
Newer Dataset Path – The path of the newer dataset.
-
Older Dataset Path – The path of the older dataset.
-
Output Path – The target path for the output of the merge job.